19 min to read
Building ETL Pipeline with BigQuery and Dataflow
A comprehensive guide to data ETL process using GCP services
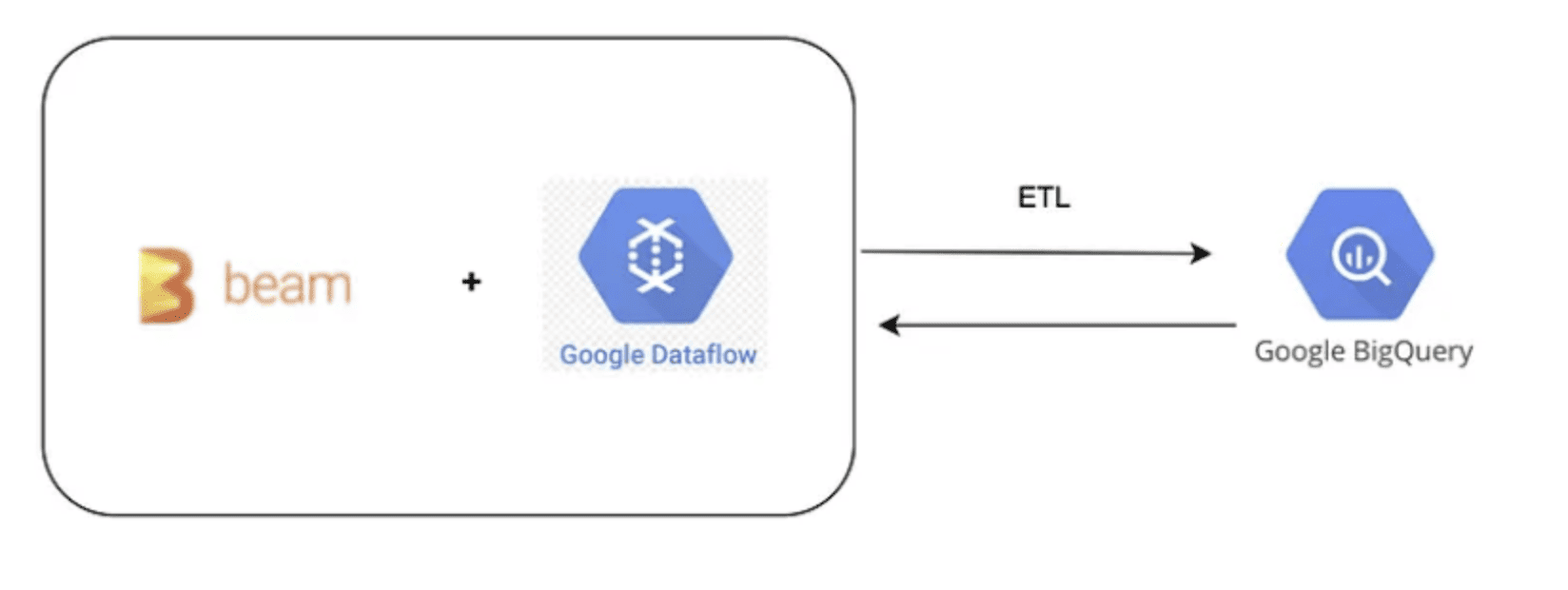
 Overview
Overview
Modern data pipelines are essential for organizations to transform raw data into actionable insights. Following our previous post about BigQuery, this guide explores how to build a robust ETL (Extract, Transform, Load) pipeline using Google Cloud Platform’s managed services, focusing on moving data from MongoDB to BigQuery and finally to Google Sheets for analysis and visualization.
This comprehensive tutorial will guide you through building a fully automated data pipeline with the following flow:
MongoDB → BigQuery → Google Sheets
ETL (Extract, Transform, Load) is a three-phase process for integrating data from multiple sources into a single data repository:
- Extract: Retrieving data from source systems (databases, APIs, files)
- Transform: Converting data to appropriate format with operations like filtering, sorting, aggregating, joining, cleaning, and validation
- Load: Writing the transformed data to a target destination (data warehouse, database, file)
Cloud-based ETL solutions like the one we're building offer advantages including scalability, reduced maintenance, cost-effectiveness, and integration with other cloud services.
GCP Services Overview
Our ETL pipeline leverages several key Google Cloud Platform services:
| Service | Role in Pipeline | Key Capabilities |
|---|---|---|
| Cloud Dataflow | Data processing engine | Batch/stream processing, auto-scaling, managed infrastructure |
| BigQuery | Data warehouse | Serverless storage and analytics, SQL interface, high-performance |
| Cloud Functions | Serverless code execution | Event-driven processing, automatic scaling, pay-per-use |
| Cloud Scheduler | Job scheduling | Managed cron jobs, reliable triggering, timezone support |
| Cloud Storage | Function code storage | Highly durable object storage, global access, integration with other services |
Cloud Dataflow Deep Dive
What is Google Cloud Dataflow?
Google Cloud Dataflow is a fully managed service for executing Apache Beam pipelines within the Google Cloud Platform ecosystem. It handles both batch and streaming data processing scenarios with automatic resource management and dynamic work rebalancing.
Dataflow Architecture
When a Dataflow job is launched, the service:
- Takes your pipeline code (Apache Beam)
- Optimizes it into an execution graph
- Splits the workload into multiple steps
- Distributes these steps across Compute Engine instances
- Manages scaling, fault tolerance, and worker communication
This abstraction allows developers to focus on pipeline logic rather than infrastructure management.
Key Features and Benefits
- Unified Programming Model
- Apache Beam SDK provides a single programming model for both batch and streaming
- Same code can run on multiple execution engines
- Supported languages include Java, Python, Go, and more
- No-Ops Data Processing
- Fully managed service with automatic provisioning and scaling
- Hands-off infrastructure management
- Dynamic work rebalancing for optimal throughput
- Built-in monitoring and logging
- Advanced Processing Capabilities
- Native handling of late and out-of-order data
- Exactly-once processing guarantees
- Windowing for time-based aggregations
- Watermarking for tracking event time progress
- Performance and Scalability
- Horizontal scaling to handle varying workloads
- Fusion optimization to minimize overhead
- Auto-tuning of worker resources
- Support for persistent disks and SSDs for performance-sensitive operations
Sample Dataflow Pipeline Code
Here’s a simplified example of a Python Dataflow pipeline that reads from MongoDB, performs transformations, and writes to BigQuery:
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.io.mongodbio import ReadFromMongoDB
from apache_beam.io.gcp.bigquery import WriteToBigQuery
# Define pipeline options including GCP project and Dataflow runner
options = PipelineOptions([
'--project=your-gcp-project',
'--region=us-central1',
'--runner=DataflowRunner',
'--temp_location=gs://your-bucket/temp',
'--staging_location=gs://your-bucket/staging'
])
# Schema for BigQuery table
schema = {
'fields': [
{'name': 'id', 'type': 'STRING'},
{'name': 'name', 'type': 'STRING'},
{'name': 'value', 'type': 'FLOAT'},
{'name': 'timestamp', 'type': 'TIMESTAMP'}
]
}
# MongoDB connection URI
uri = "mongodb+srv://username:password@cluster.mongodb.net"
# Create and run the pipeline
with beam.Pipeline(options=options) as p:
(p
| 'ReadFromMongoDB' >> ReadFromMongoDB(
uri=uri,
db='your_database',
coll='your_collection')
| 'TransformData' >> beam.Map(lambda doc: {
'id': str(doc['_id']),
'name': doc.get('name', ''),
'value': float(doc.get('value', 0)),
'timestamp': doc.get('created_at').timestamp()
})
| 'WriteToBigQuery' >> WriteToBigQuery(
table='your-project:your_dataset.your_table',
schema=schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE)
)
Cloud Functions and Scheduler
Cloud Functions
Google Cloud Functions is a lightweight, event-driven, serverless compute platform that allows you to create single-purpose, stand-alone functions that respond to cloud events without managing the underlying infrastructure.
When to Use Cloud Functions vs. Dataflow
In our ETL pipeline, we're using Cloud Functions for orchestration and simpler data movement tasks, while Dataflow would be better suited for:
- Processing very large datasets (TB+)
- Complex data transformations requiring parallel processing
- Streaming data scenarios with windowing requirements
- Pipelines that need sophisticated fault tolerance
Cloud Functions is ideal for event-triggered actions, lightweight processing, and gluing together different GCP services, as we're using it in this workflow.
Key Features
- Event-Driven: Triggers include HTTP requests, Cloud Storage events, Pub/Sub messages, and Firestore events
- Stateless: Each invocation is independent, with no persistent state between executions
- Automatic Scaling: Scales from zero to many instances based on load
- Runtime Support: Node.js, Python, Go, Java, .NET, Ruby, and PHP
- Pay-per-use: Billed by compute time in 100ms increments
Cloud Scheduler
Google Cloud Scheduler is a fully managed enterprise-grade cron job scheduler that allows you to schedule virtually any job, including batch jobs, big data jobs, cloud infrastructure operations, and more.
Key Features
- Reliability: Google-grade reliability with SLA
- Cron Syntax: Familiar unix-cron format for job definitions
- Flexible Targets: HTTP/S endpoints, Pub/Sub topics, App Engine applications
- Authentication: Support for OIDC tokens, basic auth, and OAuth
- Monitoring: Integrated with Cloud Monitoring for observability
- Retry Logic: Configurable retry on failed jobs
Example Code: MongoDB to BigQuery Function
Here’s a sample Cloud Function that extracts data from MongoDB and loads it into BigQuery:
import os
import pymongo
from google.cloud import bigquery
from datetime import datetime
def mongodb_to_bigquery(request):
# MongoDB connection
client = pymongo.MongoClient(os.environ.get('MONGODB_URI'))
db = client[os.environ.get('MONGODB_DB')]
collection = db[os.environ.get('MONGODB_COLLECTION')]
# Get data from MongoDB
cursor = collection.find({})
# Transform data for BigQuery
rows = []
for document in cursor:
# Convert MongoDB ObjectId to string
document['_id'] = str(document['_id'])
# Convert any datetime objects to string
for key, value in document.items():
if isinstance(value, datetime):
document[key] = value.isoformat()
rows.append(document)
# BigQuery client
client = bigquery.Client()
table_id = f"{os.environ.get('BIGQUERY_PROJECT')}.{os.environ.get('BIGQUERY_DATASET')}.{os.environ.get('BIGQUERY_TABLE')}"
# Load data into BigQuery
errors = client.insert_rows_json(table_id, rows)
if errors:
return f"Encountered errors: {errors}", 500
else:
return f"Successfully loaded {len(rows)} rows to {table_id}", 200
Example Code: BigQuery to Google Sheets Function
Here’s a sample Cloud Function that extracts data from BigQuery and loads it into Google Sheets:
import os
import gspread
from google.cloud import bigquery
from google.oauth2 import service_account
from datetime import datetime
def bigquery_to_sheets(request):
# BigQuery setup
bq_client = bigquery.Client()
# Query data from BigQuery
query = f"""
SELECT *
FROM `{os.environ.get('BIGQUERY_PROJECT')}.{os.environ.get('BIGQUERY_DATASET')}.{os.environ.get('BIGQUERY_TABLE')}`
LIMIT 1000
"""
query_job = bq_client.query(query)
rows = query_job.result()
# Transform data for Google Sheets
headers = [field.name for field in query_job.schema]
data = [headers]
for row in rows:
data.append([str(row[field]) for field in headers])
# Google Sheets setup
credentials = service_account.Credentials.from_service_account_file(
'bigquery.json',
scopes=['https://www.googleapis.com/auth/spreadsheets']
)
gc = gspread.authorize(credentials)
# Open the spreadsheet and write data
sheet = gc.open_by_key(os.environ.get('SHEET_ID')).worksheet(os.environ.get('SHEET_NAME'))
sheet.clear()
sheet.update('A1', data)
return f"Successfully updated Google Sheet with {len(data)-1} rows of data", 200
Complete ETL Workflow Implementation
Our complete ETL workflow follows this sequence:
Step-by-Step Implementation
1. Enable Required API Services
# Enable required APIs
gcloud services enable dataflow.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable cloudfunctions.googleapis.com
gcloud services enable cloudscheduler.googleapis.com
gcloud services enable storage.googleapis.com
gcloud services enable sheets.googleapis.com
2. Set Up Service Accounts and Permissions
# Create service account for BigQuery operations
gcloud iam service-accounts create bigquery-sa \
--display-name="BigQuery Service Account"
# Grant necessary permissions
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:bigquery-sa@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:bigquery-sa@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/bigquery.jobUser"
# Create and download key for the service account
gcloud iam service-accounts keys create bigquery.json \
--iam-account=bigquery-sa@$PROJECT_ID.iam.gserviceaccount.com
3. Create BigQuery Dataset and Tables
# Create dataset
bq mk --dataset $PROJECT_ID:analytics_data
# Create table with schema
bq mk --table \
$PROJECT_ID:analytics_data.mongodb_data \
_id:STRING,name:STRING,value:FLOAT,timestamp:TIMESTAMP
4. Set Up Cloud Storage for Function Code
# Create buckets for function code
gsutil mb -l us-central1 gs://$PROJECT_ID-functions
5. Prepare and Deploy MongoDB to BigQuery Function
# Create function directory and files
mkdir -p mongodb-to-bigquery
cd mongodb-to-bigquery
# Create requirements.txt
cat > requirements.txt << 'EOF'
pymongo==4.3.3
google-cloud-bigquery==3.9.0
EOF
# Create main.py with the function code
# (Use the MongoDB to BigQuery function code from above)
# Zip the function code
zip -r mongodb-to-bigquery.zip main.py requirements.txt
# Upload to Cloud Storage
gsutil cp mongodb-to-bigquery.zip gs://$PROJECT_ID-functions/
# Deploy the function
gcloud functions deploy mongodb-to-bigquery \
--runtime python39 \
--trigger-http \
--allow-unauthenticated \
--entry-point=mongodb_to_bigquery \
--source=gs://$PROJECT_ID-functions/mongodb-to-bigquery.zip \
--set-env-vars=MONGODB_URI=mongodb+srv://username:password@cluster.mongodb.net,MONGODB_DB=your_database,MONGODB_COLLECTION=your_collection,BIGQUERY_PROJECT=$PROJECT_ID,BIGQUERY_DATASET=analytics_data,BIGQUERY_TABLE=mongodb_data
6. Prepare and Deploy BigQuery to Google Sheets Function
# Create function directory and files
mkdir -p bigquery-to-sheets
cd bigquery-to-sheets
# Create requirements.txt
cat > requirements.txt << 'EOF'
google-cloud-bigquery==3.9.0
gspread==5.7.2
google-auth==2.16.2
EOF
# Copy the service account key
cp ../bigquery.json .
# Create main.py with the function code
# (Use the BigQuery to Google Sheets function code from above)
# Zip the function code
zip -r bigquery-to-sheets.zip main.py requirements.txt bigquery.json
# Upload to Cloud Storage
gsutil cp bigquery-to-sheets.zip gs://$PROJECT_ID-functions/
# Deploy the function
gcloud functions deploy bigquery-to-sheets \
--runtime python39 \
--trigger-http \
--allow-unauthenticated \
--entry-point=bigquery_to_sheets \
--source=gs://$PROJECT_ID-functions/bigquery-to-sheets.zip \
--set-env-vars=BIGQUERY_PROJECT=$PROJECT_ID,BIGQUERY_DATASET=analytics_data,BIGQUERY_TABLE=mongodb_data,SHEET_ID=your-sheet-id,SHEET_NAME=Sheet1
7. Set Up Cloud Scheduler Jobs
# Create scheduler for MongoDB to BigQuery (runs daily at 1 AM)
gcloud scheduler jobs create http mongodb-to-bigquery-job \
--schedule="0 1 * * *" \
--uri="https://us-central1-$PROJECT_ID.cloudfunctions.net/mongodb-to-bigquery" \
--http-method=GET \
--time-zone="America/New_York"
# Create scheduler for BigQuery to Google Sheets (runs daily at 2 AM)
gcloud scheduler jobs create http bigquery-to-sheets-job \
--schedule="0 2 * * *" \
--uri="https://us-central1-$PROJECT_ID.cloudfunctions.net/bigquery-to-sheets" \
--http-method=GET \
--time-zone="America/New_York"
Infrastructure as Code (IaC) Implementation
For production environments, it’s recommended to use Infrastructure as Code tools to automate and version your ETL pipeline setup. Below are two approaches using popular IaC tools.
Terraform Implementation
Terraform Benefits for ETL Pipelines
- Version Control: Track changes to your infrastructure over time
- Repeatability: Consistently deploy the same environment across stages
- Modularity: Reuse components across different pipelines
- Dependency Management: Automatically handle resource dependencies
- State Management: Track the actual state of resources vs. desired state
The complete implementation is available at: terraform-infra-gcp
somaz-bigquery-project/
├── README.md
├── bigquery-to-google-sheet
│ ├── bigquery.json
│ ├── main.py
│ ├── main.py.all_data
│ ├── main.py.date
│ ├── main.py.single_db
│ ├── main.py.time_UTC
│ └── requirements.txt
├── bigquery.tfvars
├── cloud-storage.tf
├── locals.tf
├── mongodb-bigquery-googlesheet-workflow.tf
├── mongodb-to-bigquery
│ ├── MongoDB_to_BigQuery
│ ├── main.py
│ ├── main.py.local
│ ├── main.py.single_db
│ └── requirement.txt
├── provider.tf
├── terraform-backend.tf
└── variables.tf
Key Terraform resource types used:
google_storage_bucket: For function code storagegoogle_cloudfunctions_function: For serverless ETL functionsgoogle_cloud_scheduler_job: For scheduling ETL tasksgoogle_bigquery_dataset: For data storagegoogle_bigquery_table: For structured data tables
Pulumi Implementation
Pulumi offers a more programmatic approach to infrastructure as code, allowing you to use familiar languages like Python:
The complete implementation is available at: pulumi-study
bigdata-flow-functions/
├── Pulumi.yaml
├── README.md
├── __main__.py
├── bigquery-to-google-sheet
│ ├── bigquery.json
│ ├── main.py
│ ├── main.py.all_data
│ ├── main.py.date
│ ├── main.py.single_db
│ ├── main.py.time_UTC
│ └── requirements.txt
├── bq_dataset.py
├── bq_sheet_archive.py
├── bq_sheet_function.py
├── config.py
├── mdb_bq_archive.py
├── mdb_bq_function.py
├── mongodb-to-bigquery
│ ├── main.py
│ ├── main.py.local
│ ├── main.py.single_db
│ └── requirements.txt
├── requirements.txt
├── scheduler_manager.py
├── storage.py
└── utils.py
Advanced Customization and Optimizations
Handling Different Data Types
The provided code examples can be customized for different MongoDB collections and data structures:
main.py.all_data: Processes complete collectionsmain.py.date: Filters data by date rangesmain.py.single_db: Works with single MongoDB databasesmain.py.time_UTC: Handles timezone conversions
Scaling Considerations
As your data volumes grow, consider these optimizations:
- BigQuery Partitioning: Partition tables by date for improved query performance and cost
CREATE TABLE analytics_data.mongodb_data PARTITION BY DATE(timestamp) AS SELECT * FROM analytics_data.mongodb_data_temp - Batch Processing: Process data in manageable chunks
# Process in batches of 1000 documents batch_size = 1000 total_docs = collection.count_documents({}) for i in range(0, total_docs, batch_size): cursor = collection.find({}).skip(i).limit(batch_size) # Process batch - Error Handling: Implement robust error handling and retries
from google.api_core.retry import Retry @Retry(predicate=Exception, deadline=60.0) def insert_with_retry(client, table_id, rows): errors = client.insert_rows_json(table_id, rows) if errors: raise Exception(f"Error inserting rows: {errors}") return len(rows) - Monitoring: Set up alerts for pipeline failures
from google.cloud import monitoring_v3 def create_failure_alert(project_id): client = monitoring_v3.AlertPolicyServiceClient() # Create alert policy configuration # ...
Best Practices and Lessons Learned
Security Best Practices
- Principle of Least Privilege: Grant only required permissions to service accounts
- Secret Management: Store sensitive credentials securely using Secret Manager
- VPC Service Controls: Implement network security boundaries for sensitive data
- Audit Logging: Enable comprehensive logging for all data access
Performance Optimization
- BigQuery Best Practices:
- Use partitioning and clustering
- Filter on partitioned columns
- Select only needed columns
- Use approximate aggregation functions when possible
- Cloud Functions Performance:
- Increase memory allocation for CPU-intensive tasks
- Keep functions stateless and idempotent
- Reuse connections to external services
- Cost Optimization:
- Set up budget alerts
- Use BigQuery flat-rate pricing for predictable workloads
- Schedule less frequent updates for non-critical data
Next Steps and Future Improvements
This ETL pipeline can be extended in several ways:
- Real-time Processing: Implement streaming data ingestion using Pub/Sub and Dataflow
- Data Quality Checks: Add validation steps to ensure data integrity
- Advanced Analytics: Implement BigQuery ML for predictive analytics
- Visualization: Connect to Data Studio or Looker for rich dashboards
- CI/CD Pipeline: Set up automated testing and deployment
In future articles, we’ll explore these advanced topics in greater detail.

Comments