5 min to read
Kubernetes Headless Services
Overview
Kubernetes Headless Services provide direct pod access without load balancing or cluster IP assignment, making them ideal for stateful applications and databases.
Key Features
No Cluster IP
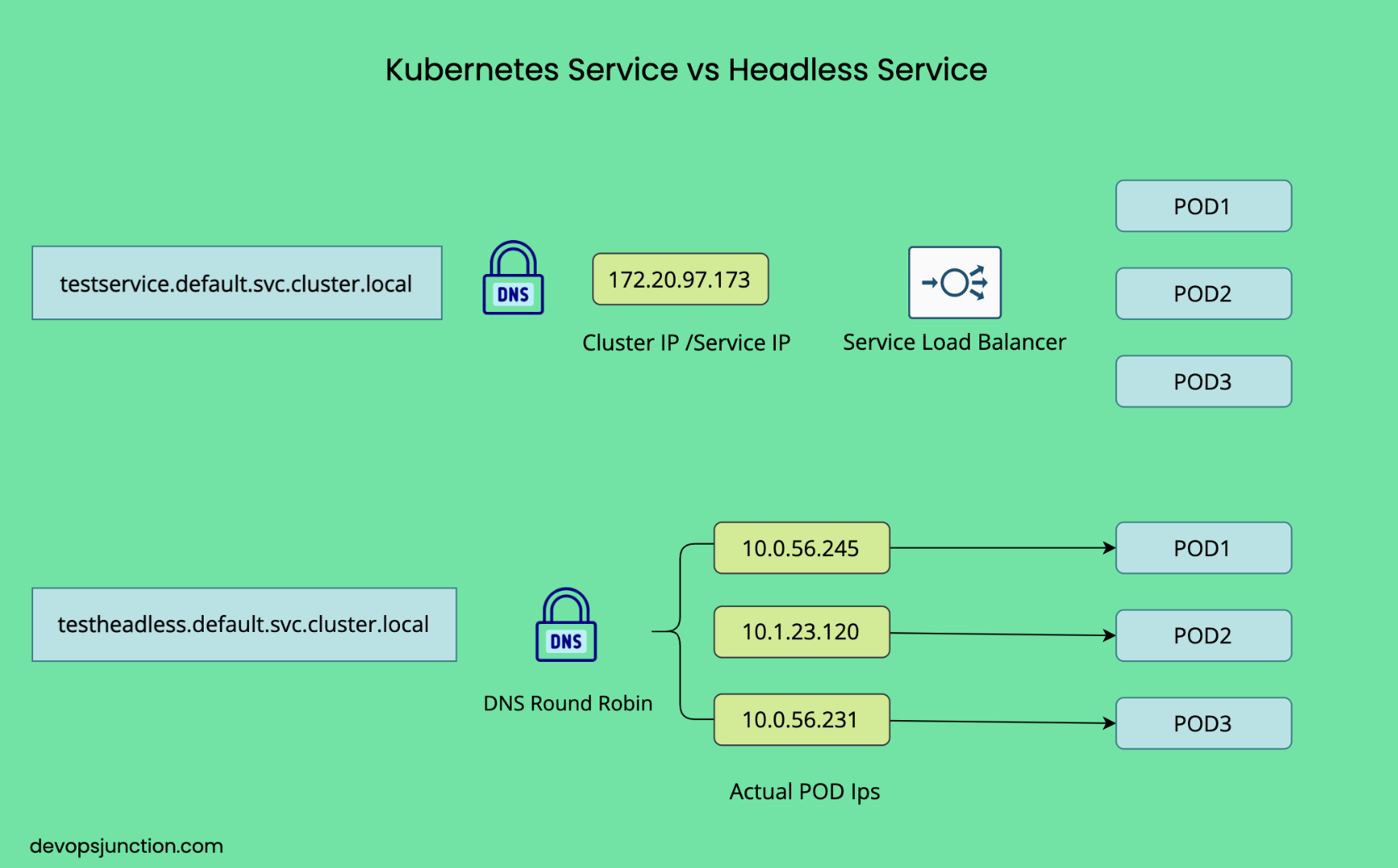
- Headless service is created by setting spec.clusterIP to None. This means that Kubernetes does not assign a virtual IP to the service.
DNS Records for Pods
- Instead of routing traffic through a load balancer, Kubernetes creates a separate DNS record for each pad. These DNS records allow clients to connect directly to a particular pad.
Direct Pod Communication
- An application or service may communicate directly with the pad by bypassing the typical service abstraction that provides load balancing.
Common Use Cases
- Headless Services are commonly used with Stateful Sets, where each pod must have a unique ID and be able to address it individually.
- It is also used for certain types of applications, such as databases that require direct access to individual pods for clustering (e.g., Cassandra, Kafka, MongoDB).
Benefits of Headless Service
Segmented pas Access
- Direct access to the pad is essential for applications that require node-specific tasks or status.
Simplified DNS management
- Kubernetes automatically manages DNS records for each pad in the Headless Service.
Stateful application support
- It is useful for StatefulSet and distributed databases where continuous ID and connection are important.
How Headless Service Works
When you create Headless Service, Kubernetes generates DNS records differently.
- For a typical service, a single DNS entry refers to the cluster IP of the service.
- For Headless Service, a DNS item is created for each pad. For example, if there is a Headless Service named
my-servicewith three pads in the default namespace, the DNS record is displayed as follows.
my-service.default.svc.cluster.local -> No IP (headless service)
pod-0.my-service.default.svc.cluster.local -> Pod-0 IP
pod-1.my-service.default.svc.cluster.local -> Pod-1 IP
pod-2.my-service.default.svc.cluster.local -> Pod-2 IP
Create Headless Service
An example of a YAML configuration for Headless Service is as follows.
apiVersion: v1
kind: Service
metadata:
name: headless-service
spec:
clusterIP: None # This makes it headless
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
Integration with StatefulSet
StatefulSet often manages the pas network ID using the Headless Service. Each pas has a unique network ID and can be individually addressed.
- For example, StatefulSet, named Web, and Web, named Headless Service, generate a pad with the following DNS names.
web-0.headless-service.default.svc.cluster.local
web-1.headless-service.default.svc.cluster.local
web-2.headless-service.default.svc.cluster.local
Headless Service DNS Query Behavior
A/AAAA DNS query (default)
- When you query the DNS name my-service.default.svc.cluster.local for Headless Service, Kubernetes returns the IP addresses of all matching Pod (Endpoint). That is, the DNS response includes multiple IP addresses (one for each Pod that supports the service).
nslookup my-service.default.svc.cluster.local
Name: my-service.default.svc.cluster.local
Address: 10.1.2.3
Address: 10.1.2.4
Address: 10.1.2.5
- Deployment behavior : When an application is connected to my-service.default.svc.cluster.local, the distribution of the request depends on how the client handles multiple IPs. Many clients select one IP at random or in a round-robin manner.
SRV Records
- Kubernetes also generates SRV DNS records for Headless Services, including DNS names and ports of individual pods. These records are useful if an application can utilize SRV records for service retrieval.
dig SRV my-service.default.svc.cluster.local
;; ANSWER SECTION:
my-service.default.svc.cluster.local. 30 IN SRV 0 50 8080 pod-0.my-service.default.svc.cluster.local.
my-service.default.svc.cluster.local. 30 IN SRV 0 50 8080 pod-1.my-service.default.svc.cluster.local.
my-service.default.svc.cluster.local. 30 IN SRV 0 50 8080 pod-2.my-service.default.svc.cluster.local.
Will Requests Be Distributed?
Requests for my-service.default.svc.cluster.local are not inherently load balanced by Kubernetes in the Headless Service.
- Instead, DNS resolution provides multiple IPs (one per Pod), and the client decides which IP to use.
- The DNS recognition client may perform the following.
- Choose one IP at random.
- Do the first IP of the list.
- All IPs are used in a round robin manner.
- Cache DNS results for a specific period of time that may affect deployment.
- If the client does not implement load balancing directly, traffic may not be evenly distributed.
Key differences from ClusterIP services
For regular ClusterIP services
- Kubernetes allocates a single cluster IP, and all requests are automatically load balanced across the Pod.
- The client does not have to deal with multiple IPs.
For Headless Service
- There is no cluster IP and no built-in load balancing.
- Clients need to handle multiple Pod IPs directly.
Service Comparison Table
| Feature | Headless Service | Regular Service |
|---|---|---|
| ClusterIP | None | Assigned |
| Load Balancing | No | Yes |
| DNS Records | Per Pod | Single Service |
| Direct Pod Access | Yes | No |
Conclusion
When accessing my-service.default.svc.cluster.local, traffic is not automatically distributed by Kubernetes.
- DNS checks the Pod IP list.
- The client decides how to process the corresponding list (e.g., random selection, round robin).
If you do not want to use Headless Service
- If load balancing is required, you can use the regular ClusterIP, NodePort, or LoadBalancer service instead.
- For applications that do not require direct access to individual Pod, standard service is sufficient.


Comments