5 min to read
Safe Pod Termination in Kubernetes - A Complete Guide
Overview
Managing Pod termination safely is crucial in Kubernetes operations, especially during maintenance, updates, or scaling activities.
Pod Management Commands
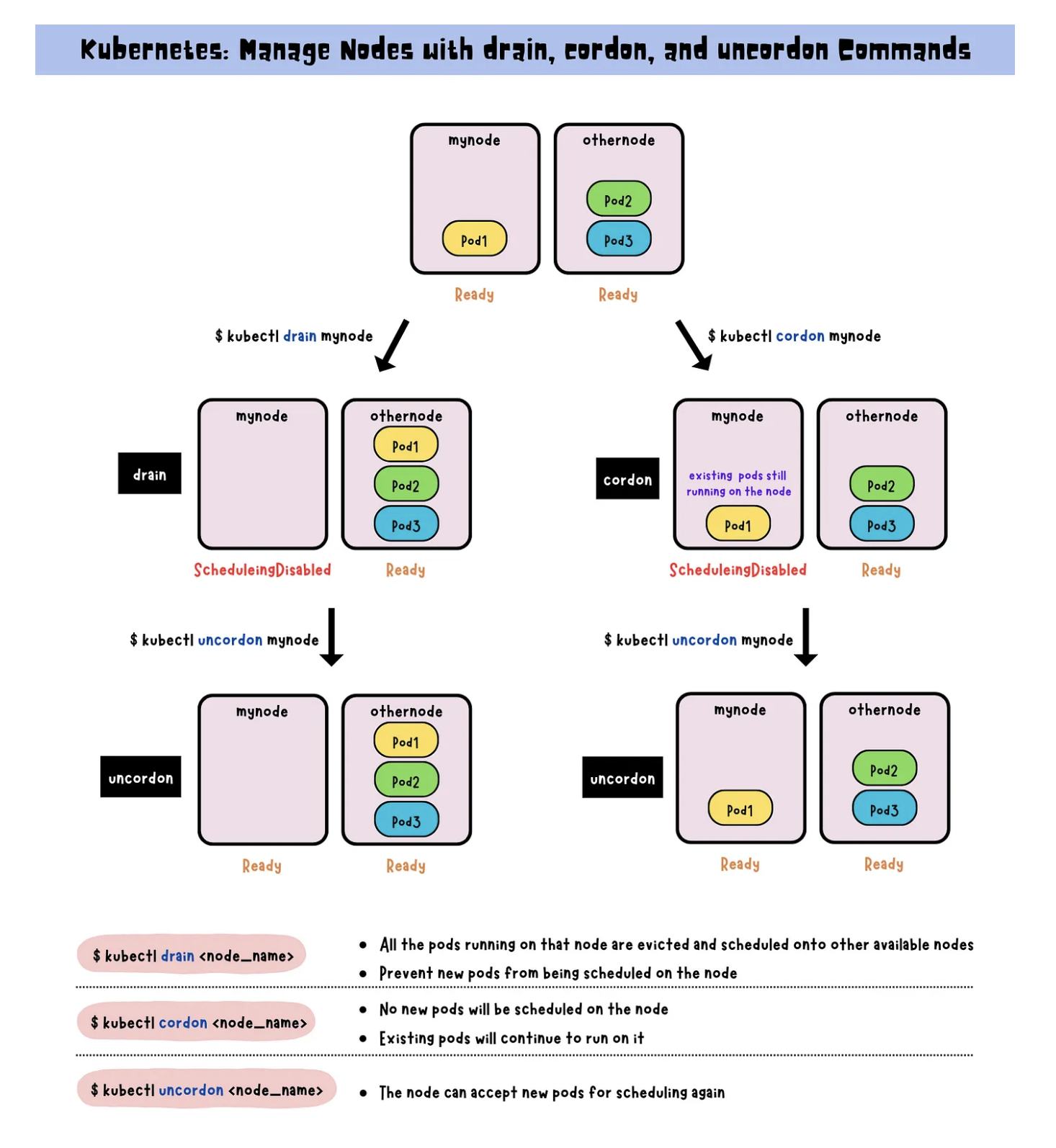
In Kubernetes, Pod termination can be handled in several ways depending on operational requirements such as maintenance, update, or extension operations.
Next, we will learn how to safely manage Pod termination using Kubernetes commands such as cordon, uncordon, drain, and scale.
# Cordon - Mark node as unschedulable
kubectl cordon <node-name>
# Uncordon - Mark node as schedulable
kubectl uncordon <node-name>
# Drain - Safely evict pods from node
kubectl drain <node-name> --ignore-daemonsets --delete-local-data
# Scale - Adjust replica count
kubectl scale --replicas=0 deployment <deployment-name> -n <namespace>
kubectl scale --replicas=0 statefulset <statefulset-name> -n <namespace>
- ignore-daemonsets: Ignore daemonsets on the node
- delete-local-data: Delete local data on the node
StatefulSet vs Stateless Applications
For tasks that require safe shutdown and re-run of Pod, it is common to use the Scale command to make Replica 0.
StatefulSet
Scale down progressively: Reducing the number of replicas in StatefulSet triggers controlled termination of the pad, starting with the highest order. This is important for applications that need to end in order (e.g., databases).
For example, MariaDB Galera Cluster should be terminated after 2 → 1 → 0 sequentially scaling.
# StatefulSet Progressive Scaling
# Example for MariaDB Galera Cluster
kubectl scale --replicas=2 sts app-db -n <namespace>
kubectl scale --replicas=1 sts app-db -n <namespace>
kubectl scale --replicas=0 sts app-db -n <namespace>
# Stateless Direct Scaling
kubectl scale --replicas=0 deploy api -n <namespace>
Stateless
Direct scaling or deletion: Stateless applications do not remain internal, allowing you to scale back or delete pods without much concern for data consistency.
If you are using a general stateless application, you can scale directly to replicas=0 as follows.
kubectl scale --replicas=0 deploy api -n <namespace>
Additional Considerations
- Pod Interruption Budget (PDB): Define PDB so that minimal pods continue to run during the removal process.
- Step-by-step shutdown: Configure the application to process the SIGTERM signal and terminate normally when Kubernetes sends these signals during Pod removal.
- Monitoring: Always monitor the status and performance of applications, especially during extended operations and node maintenance.
Pod Disruption Budget (PDB)
Pod Disruption Budget (PDB) is a Kubernetes resource that helps ensure that a specified minimum number of Pods are available during volatile disruption.
This is particularly important for maintaining the availability and resilience of applications during tasks that may affect Pod availability, such as node maintenance, cluster upgrades, or other disruptions managed by cluster administrators.
Here, volatile disturbances include all commands such as cordon, uncordon, drain, and scale. Voluntary disturbances are typically planned tasks that can be controlled and scheduled at times that minimize impact on applications.
This is different from invitational disturbances such as unpredictable and unmanageable hardware errors or unexpected node loss in PDB.
PDB Example
- MinAvailable: The minimum number of available pods that should always work during interruption.
- MaxUnavailable: The maximum number of pods that cannot be used during interruption.
The PDB ensures that the Kubernetes system complies with the limitations set by the PDB, even during volitional interruptions, so that there is no significant impact on application performance and availability.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-app-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: my-app
- Ensure that more than one labeled pad stays operational at all times app: my-app.
- In other words, it means that even if the DB is scaled, it always retains two.
🔄 Node Management Workflow
Cordon, uncordon, and drain commands are used to upgrade and maintain Node and Pod.
1. Drain Process:
- Automatically cordons node
- Safely evicts pods
- Respects PDB
- Waits for pod termination
2. Maintenance Steps:
- Cordon: Prevent new pod scheduling
- Perform maintenance
- Uncordon: Re-enable pod scheduling
3. Best Practices:
- Always check PDB settings
- Monitor pod health
- Plan maintenance windows
⚙️ Kubernetes Node Management Commands
| 🔧 Command | 📄 Purpose | 📦 Impact on Pods | 🖥️ Impact on Node |
|---|---|---|---|
🚫 cordon |
Mark node as unschedulable | ❌ None | ⛔ Prevents new pods from being scheduled |
✅ uncordon |
Mark node as schedulable | ❌ None | ✔️ Allows new pods to be scheduled |
📤 drain |
Evacuate all pods from the node | 🚪 Evicts all pods | 🚫 Marks node as unschedulable |
📈 scale |
Adjust the number of pod replicas | ➕➖ Adds or removes pods | ✔️ No impact on node |
-
Pod Disruption Budgets
- Define minimum available pods
- Ensure service availability
- Handle voluntary disruptions -
Graceful Termination
- Respect SIGTERM signals
- Handle shutdown procedures
- Monitor termination process -
Application State
- Consider stateful vs stateless
- Manage data persistence
- Plan scaling operations

Comments